AWS-GCP 混合雲高可用架構
WordPress 跨雲災難復原技術說明文檔
系統架構總覽
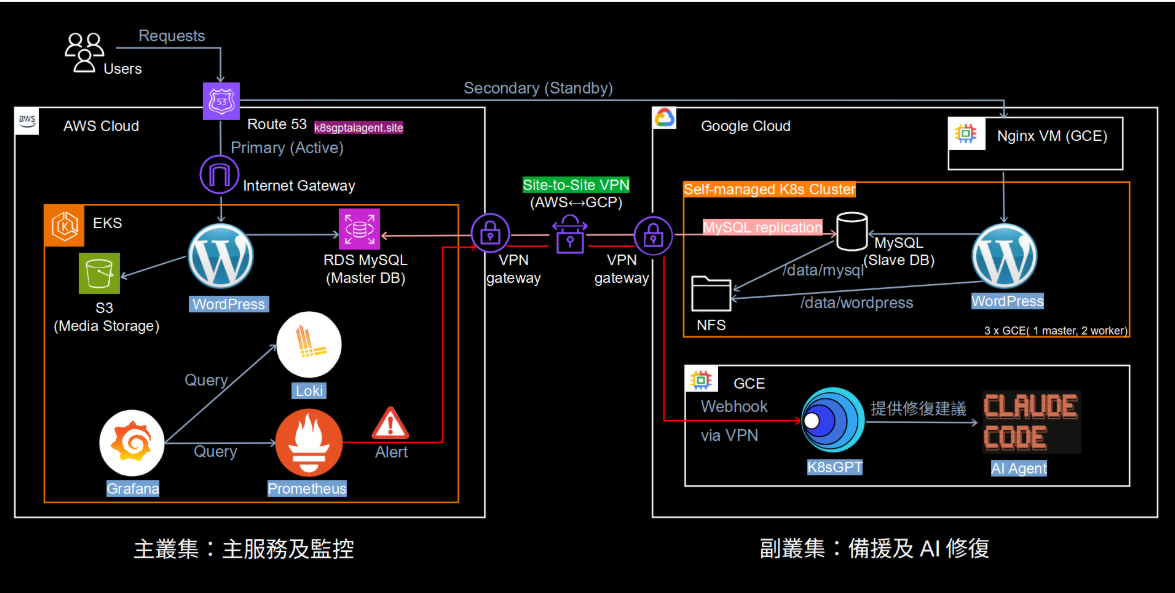
展示 AWS 主服務(EKS、RDS)與 GCP 備援環境(Kubeadm、MySQL Replica)的整體架構
包含 Route 53 流量管理、VPN 連接及 Claude AI 智能監控整合
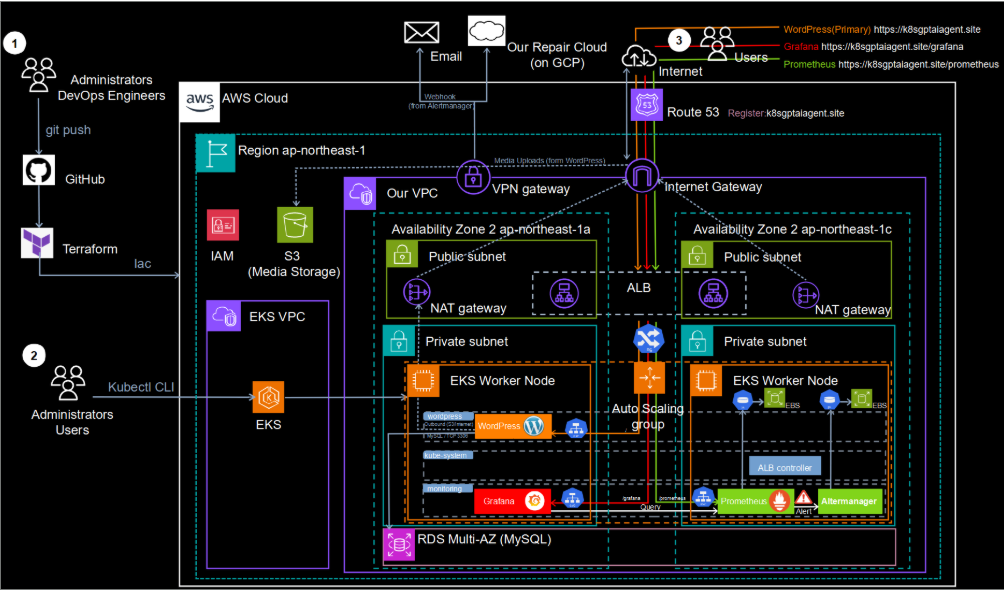
AWS 主從集群的詳細架構圖,涵蓋 VPC 網路設計、子網規劃、
安全群組、ALB 負載均衡器、Terraform 自動化部署及 GitHub CI/CD 流程
×
![]()
1.網路流量路徑
正常運作流量路徑
👤 用戶
→
🌐 Route53 DNS
→
⚖️ AWS ALB
→
☸️ EKS WordPress
→
💾 RDS MySQL
災難切換流量路徑
👤 用戶
→
🌐 Route53 Failover
→
🔀 GCP NodePort
→
☸️ Kubeadm WordPress
→
💾 GCP MySQL
2.資料庫複製架構
MySQL Binlog 複製流程
用戶寫入 (INSERT/UPDATE)
↓
RDS 寫入 Binary Log
↓
Binlog 透過 VPN 傳輸
↓
GCP IO Thread 讀取
↓
寫入 Relay Log
↓
SQL Thread 重放
↓
資料同步完成
| 配置項目 | AWS RDS (Master) | GCP MySQL (Slave) |
|---|---|---|
| Server ID | 1 | 2 |
| Binlog 格式 | ROW | ROW |
| 讀寫模式 | Read/Write | Read-Only |
| 複製模式 | - | 單線程 + IDEMPOTENT |
| Binlog 保留 | 168 小時 (7 天) | - |
✅ 複製狀態
Slave_IO_Running: Yes | Slave_SQL_Running: Yes | Seconds_Behind_Master: 0
3.監控與 AI 自動修復流程
告警處理與自動修復流程
📊 Prometheus
→
🔔 Alertmanager
→
🔗 Webhook
📧 Email 通知
🖥️ Control Center
→
🔍 K8sGPT
→
🤖 Claude Code
※ Webhook 觸發時同時發送 Email 通知管理員
AI Agent 決策流程
K8sGPT 分析結果
↓
偵測到錯誤?
No
↓
結束
Yes
↓
達修改次數上限?
Yes
↓
結束 (防止循環)
No
↓
Claude Code 動態產生修復腳本
↓
自動執行修復指令
| 告警規則 | 觸發條件 | 嚴重等級 |
|---|---|---|
| InstanceDown | 實例離線超過 1 分鐘 | Critical |
| PodNotRunning | Pod 狀態非 Running | Warning |
| PodRestartedMoreThanTwice | Pod 重啟次數 > 2 | Warning |
| NoAvailableReplicas | Deployment 無可用副本 | Critical |
| HighCpuUsage | CPU 使用率 > 80% | Warning |
🎬 AI 自動修復實際演示
以下是 K8sGPT + Claude Code 自動偵測並修復 Kubernetes 集群問題的實際案例演示
🔴 OOMKilled 記憶體不足修復
Pod 因記憶體不足被強制終止,AI 自動調整資源限制並重新部署
🔄 CrashLoopBackOff 修復
容器持續崩潰重啟,AI 診斷配置錯誤並自動修正
📊 ResourceQuota 超限修復
資源配額超出限制,AI 自動調整配置以符合配額要求
4.VPN 混合雲連接
IPSec VPN + BGP 連接架構
AWS VPN Gateway
ASN: 64512
⟷
ASN: 64512
IPSec Tunnel
IKEv2 + AES-256
⟷
IKEv2 + AES-256
GCP HA VPN
ASN: 65000
ASN: 65000
| 參數 | Phase 1 (IKE) | Phase 2 (IPSec) |
|---|---|---|
| 加密演算法 | AES-256-CBC | AES-256-GCM |
| 完整性 | SHA-256 | SHA-256 |
| DH 群組 | Group 14 (2048-bit) | Group 14 (PFS) |
| 生存時間 | 28800 秒 (8 小時) | |
✅ BGP 狀態
Session: Established | AWS 通告: VPC CIDR | GCP 通告: Subnet CIDR | 路由: 雙向自動傳播
5.災難恢復流程
💡 設計理念
主要依靠 Control Center 的 AI Agent 進行自動偵測與修復。只有當 kubectl 完全無法使用、整個集群都無法訪問時,才會執行 Route53 DNS Failover 切換到 GCP 備援站點。
故障處理決策流程
🚨 告警觸發
↓
K8sGPT 分析問題
↓
集群可訪問?
(kubectl 可用)
(kubectl 可用)
No (集群完全故障)
↓
Route53 DNS Failover
切換至 GCP 備援
切換至 GCP 備援
Yes
↓
Claude Code 產生修復腳本
↓
自動執行 kubectl 修復
↓
✅ 服務恢復
🤖 主要路徑:AI 自動修復
• K8sGPT 診斷問題原因
• Claude Code 動態產生修復指令
• 自動執行 kubectl 操作
• 大多數故障可在此階段解決
• Claude Code 動態產生修復指令
• 自動執行 kubectl 操作
• 大多數故障可在此階段解決
🔄 備援路徑:DNS Failover
• 僅當集群完全無法訪問時觸發
• 確認 GCP MySQL 複製狀態
• 提升 GCP MySQL 為 Primary
• Route53 切換 DNS 到 GCP
• 確認 GCP MySQL 複製狀態
• 提升 GCP MySQL 為 Primary
• Route53 切換 DNS 到 GCP
< 5 分鐘
AI 自動修復 RTO
10-15 分鐘
DNS Failover RTO
🎬 DNS Failover 實際演示
當 AWS 集群完全無法訪問時,Route53 自動將流量切換至 GCP 備援站點的實際操作過程
🔄 Route53 DNS Failover 流量切換
模擬 AWS 主站完全故障情境,演示 Route53 健康檢查失敗後自動將流量切換至 GCP 備援站點,確保服務不中斷
✅ 切換驗證重點
• Route53 健康檢查偵測到 AWS 主站異常
• 自動更新 DNS 記錄指向 GCP 備援 IP
• GCP MySQL 從 Replica 提升為 Primary
• 用戶流量無感切換至備援站點
• 自動更新 DNS 記錄指向 GCP 備援 IP
• GCP MySQL 從 Replica 提升為 Primary
• 用戶流量無感切換至備援站點
6.專案總結
高可用性 - 雙雲備份,單點故障可自動切換
資料安全 - VPN 加密傳輸,私網資料庫複製
即時同步 - 資料庫複製延遲 < 1 秒
智能監控 - K8sGPT + Claude Code 自動修復
成本優化 - 使用經濟型實例與儲存
完整 IaC - Terraform 100% 自動化部署
📋 維護建議
• 每週檢查資料庫複製狀態
• 每月測試災難恢復流程
• 定期審查 Prometheus 告警規則
• 持續監控 VPN 隧道連接質量
• 每月測試災難恢復流程
• 定期審查 Prometheus 告警規則
• 持續監控 VPN 隧道連接質量